Your view is not academic at all and has been deeply considered here. It happens that Jetty has a low-resources monitor when your start running out of memory/CPU (maybe disk space too), and we use it to define the priority of subsequent requests based on their average response time and importance. Basically, when low on resources prioritize the requests to fast and important pages, potentially dropping requests to known slow and/or less important pages. Indeed it’s better to refuse at least in some degrees new connections to give the time to the machine/software to stabilize back to normal level of resources usage.
Actively refusing requests is a sound strategy and what you are describing is similar to the circuit breaker pattern. But it does not change the fact that to be be fully asynchronous everything has to be asynchronous: when receiving requests after accepting the connections from the client and, when calling external services including the database to service the requests. In the case of the database, jdbc drivers are synchronous by design. Being asynchronous across all these layers allows to receive a lot of requests and to concurrently service them as their I/O operations progress. This contrasts to the Java world where you queue the requests and service them as threads from a thread pool become available.
Don’t trust the benchmarks!
So…
below are latest results of Clojure Web Servers from TechEmpower Web Framework Benchmarks. Added also all Erlang and Elixir entries to the views.
From the tests:
- Most Clojure web servers have good performance
- Some entries are more full-stack, some just bare-bones web servers - but the tests are the same
- At best, Clojure Web Servers are as fast as the fastest Java versions (the ring-layer can be really tiny), just 10% away from the fastest entries in any language
- In real life db-tests, the best Clojure entries are 4x slower than the fastest ones. Could be worth investigating why:
clojure.java.jdbcis not optimized for perf, but could be also because of different driver, pooling settings, not using the async driver etc.
Below are some results. NOTE: both the immutant and reitit entries use my perf-fork of Immutant, not the official release.
Return a JSON message
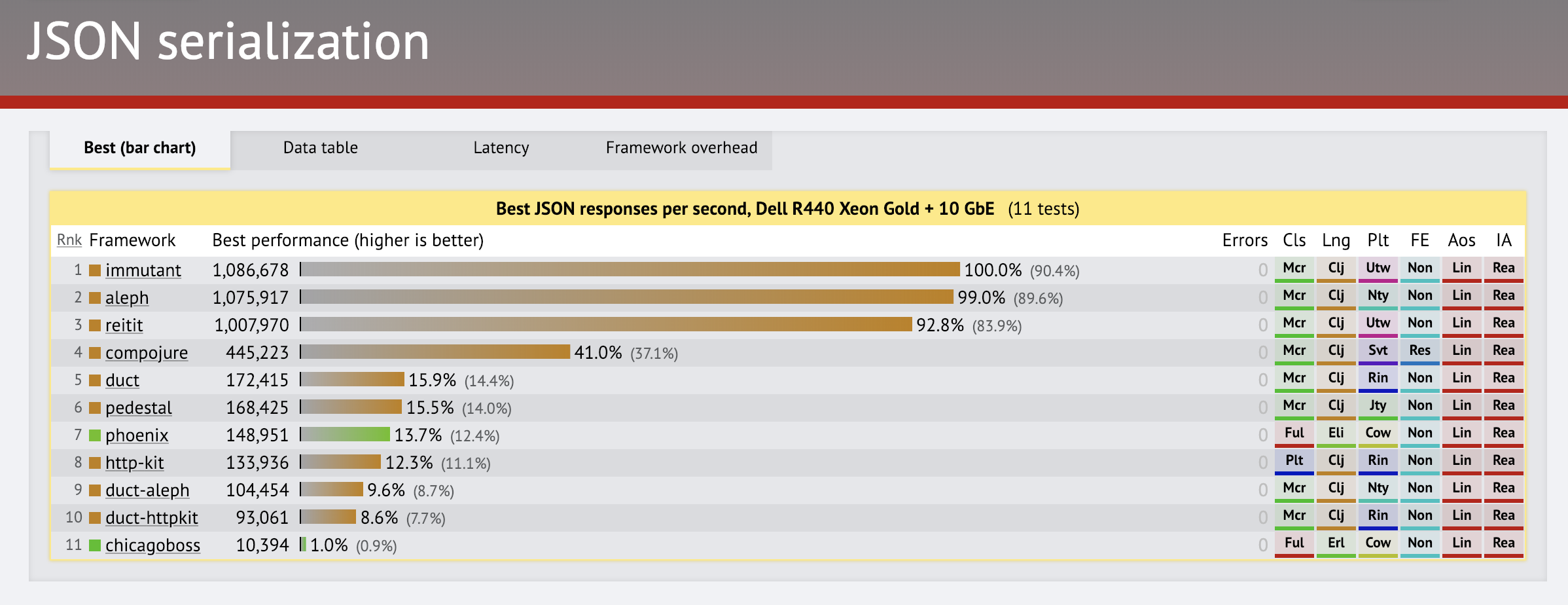
More real-life DB-test

Sync, Async
James has a nice blog about async-ring and compare it to other async approaches in Clojure.
EDIT: 4x slower
For anyone interested, I would read this: https://wiki.eclipse.org/Jetty/Feature/Continuations#Introduction
I’m not sure if Ring can leverage asynchronous servlet features though, or if this is only exposed through Java.
I think pedestal supports the servlet 3.0 api if you return a core.async channel from your interceptor.
The original question was about which web server to use but later comments reference async vs sync programming models. I think the web server itself doesn’t matter too much (I like http-kit for its simplicity) but choosing the right programming model is very important.
My view on async networking on the server:
- Asynchronous tcp connection handling is inherently more complex than a blocking synchronous alternative. Your async program is harder to reason about and stack traces are useless.
- In particular, HTTP requests are by nature well suited to blocking, synchronous handling and threads. Push events, i.e. SSE or Websockets, are a different story.
- Chances are most of what you’ll be doing will be talking to a database. Async request handling only makes sense if all network I/O is also async, including database queries. This is not easy with JDBC.
- Core.Async is useful but it really does complicate things a lot - only use if you have a real need to avoid blocking operations.
TL;DR: you should probably avoid async networking unless you have very special requirements (Push, long-running connections, thousands of concurrent TCP connections).
It happens that pedestal has very good support of core.async. If an interceptor returns a channel, the request is is considered async and non-blocking. It allows you split async I/O code and normal processing code into different interceptors and reason about/test the code sanely. I can’t speak for others, haven’t tried them.
Doesn’t change the fact that you shouldn’t go the async route unless you absolutely need to
I doubt they’re using the fastest way of interacting with the current clojure.java.jdbc: using a reducible-query with a “raw” result set. That can get pretty close to raw Java JDBC performance (see the benchmark code in the repo).
This is something I intend to focus on with next.jdbc or whatever it ends up being called,
Looking forward to next.jdbc. Also guide on how to write performant db-code with Clojure, benchmarks included 
Based on the benchmarking code you contributed to clojure.java.jdbc, here’s where we are with the reducible-query stuff as of Clojure 1.10 and the current version of clojure.java.jdbc (edited for brevity/easier comparison):
Reducible query with prepared statement and raw result set...
Execution time mean : 429.640047 ns
Reducible query with raw result set...
Execution time mean : 1.887693 µs
Raw Java...
Execution time mean : 1.225867 µs
For comparison, a simple query select runs in about 6.55 µs and a simple reducible-query with simple identifiers (i.e., reifying the result set using the minimal options) in about 3.4 µs.
I’m not yet at the point where I can run these benchmarks against next.jdbc but I believe I can hit the 2-3 µs range for this benchmark with the “default” query behavior out of the box and be very close to the Java numbers with reducible-query.
I’ll echo @pesterhazy’s comments here on not going async unless absolutely necessary. I’m using the yada framework with Deps. It uses Aleph (Netty based webserver) and the Manifold async abstractions. Yada has a really nice perspective on building HTTP compliant servers and comes with built-in interceptors to do most of the work for you.
These are all great libraries, but have had a bit of a cost for using them. Most of the Java webserver ecosystem is built around a thread/request model. This includes monitoring tools, tracing tools, logging frameworks, e.t.c. Often these libraries/frameworks use thread-local storage which is not very amenable to multi-threaded work. In some cases I’ve been able to pass the context from thread to thread in the yada ctx map, but it does add a bit more complexity. I can’t remember having any of these kinds of issues with Clojure libraries, probably because Clojure is built around immutability and passing pure data,
If you need to have async networking then I guess you need it, but be aware that you will lose some things going that route.
From what people are saying, it seems the criticism from someone coming from Go is valid. It seems Clojure maybe doesn’t have a complete story when it comes to asynchronous request handling.
You can do it, but you’ll find integration within the greater eco-system more challenging.
I think this is a bit sad, since it could have been somewhere Clojure distinguishes itself from Java.
I’m not sure I understand what people mean by “async is not that great in Clojure”. Could someone give more details?
My only experience with Web/Clojure is with pedestal, and we migrated from sync to async successfully (from a throughput POV), without adding much complexity to the code base.
I was saying from the perspective that the request handling thread should be released back to the pool everytime the handler performs IO. And on the next IO operation to complete, reallocated to continue that request.
It seems that a lot of the ecosystem isn’t fully integrated to do so. Thus it’s possible that your logging framework is sync, and breaks the model, or your monitoring library can’t keep track of async requests which have a life cycle beyond the thread. Or that some other library depends on thread local storage, etc.
To be frank though, I’m judging based on other people’s comments, because I’ve never tried to do async request handling in Clojure.
Could you please elaborate (for a beginner)?
See if this StackOverflow question (& answers) provides enough elaboration: What is Callback Hell?