Cloud Warehouse/Workshop Model
-
Everything is a pipeline: the perfect way to achieve the simplicity and unity of the software ecosystem.
-
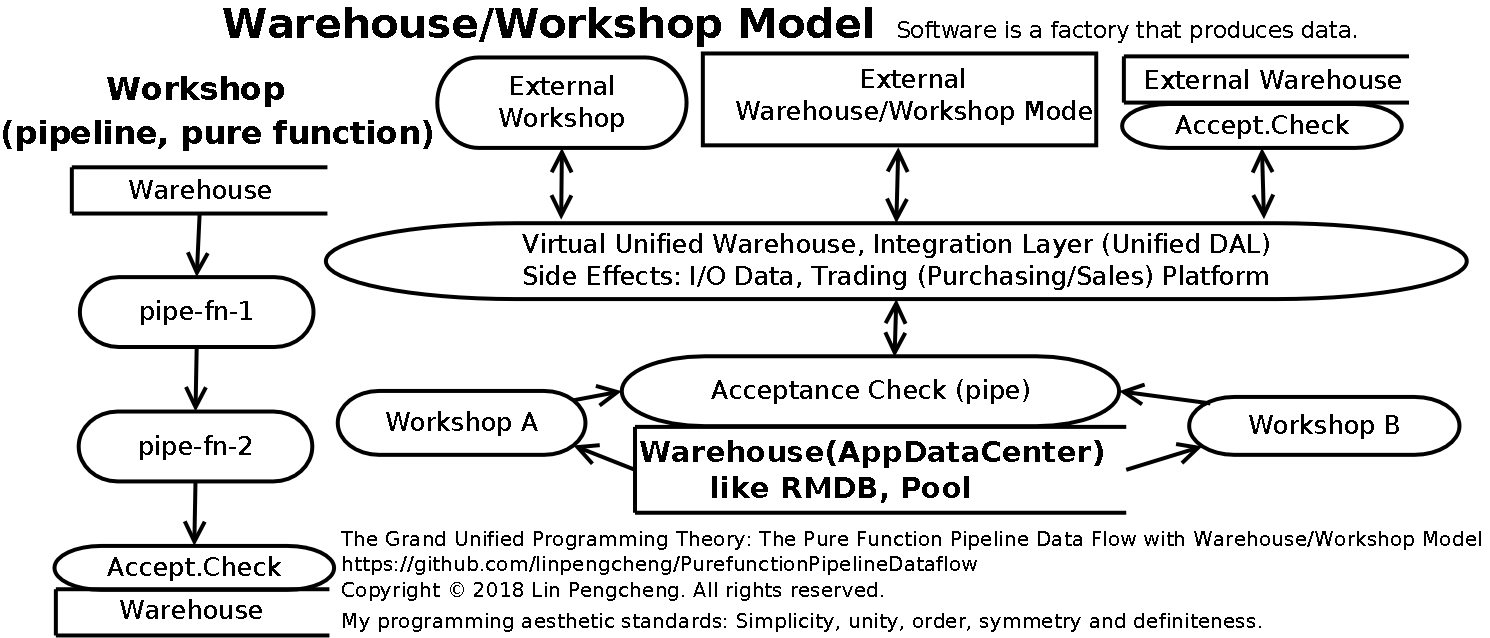
Pipeline combination: The cascade of
simple pipelinesforms aworkshop pipeline -
Workshop combination:
- Parallel independent
workshop pipelines
formwarehouse/workshop model pipelines (data factory)
throughwarehousecollaboration (scheduling). - The
workshop pipelinecan be used as apackaged integrated pipeline (integrated chip)
to independently provide services to the outside world, which is a microservice or service industry.
- Parallel independent
-
Warehouse: It can provide services as an independent entity, which is a warehousing industry or database server.
-
Warehouse/Workshop Model combination:
- Various independent
Warehouse/Workshop Model pipelines (data factory)can be used as a
packaged integrated pipeline (data factory, integrated chip)and then combined into a larger
Warehouse/Workshop Model pipeline (data factory), - This is the method of interconnection, collaboration, and integration of different developers and
different software products, and is also the basis for software development and standardization of
large-scale industrial production. - This is the corporate group or the entire industrial ecosystem.
- Various independent
-
Finally, the pipeline is like a cell, combined into a pipeline software ecosystem
that meets the requirements of the modern industrial ecosystem.
This is the perfect combination of simplicity and unity. -
Contrast with
Everything is an object- The object is a furry ball, and there is a chaotic
P2P (peer to peer) network between the objects.
It is a complex unorganized system. - The pipeline is a one-way ray,
and it’s the simplest that data standardization
and combination. It is a simple, reliable, orderly,
observable and verifiable system.
- The object is a furry ball, and there is a chaotic
-
-
Because software is a factory that produces data, so modern industrial systems are suitable for software systems.
-
Warehouse(database, pool)/Workshop(pipeline) Model is simple and practical model,
and the large industrial assembly line is the mainstream production technology in the world. -
The best task planning tool is the Gantt chart, and the best implementation method is the warehouse/workshop model implemented by the factory.
-
My programming aesthetic standards is “simplicity, unity, order, symmetry and definiteness”, they are derived from the basic principles of science. Newton, Einstein, Heisenberg, Aristotle and other major scientists hold this view. The aesthetics of non-art subjects are often complicated and mysterious, making it difficult to understand and learn. The pure function pipeline data flow provides a simple, clear, scientific and operable demonstration.