Hi all,
as you may know, I am quite fond of writing small Clojure command-line tools for a lot of my things. Lately, I started using a sqlite database for small things that I need to track (thousands of records) and I store it under git. So whatever happens, I have the backup and/or I can go back in time. Works well and I feel safe.
What I don’t like, of course, is that the database is a binary blob. So I was thinking, why not just storing a trivial EDN file? I don’t care about performance, and whatever I can do in SQL I can do in Clojure.
There is also https://github.com/riverford/durable-ref. It has file persistence baked in, and support for various other types of persistent storage if you need it.
Disclaimer: I’m writing a PR which adds redis as a possible durable storage.
Another exciting development: GitHub - replikativ/datahike: A durable Datalog implementation adaptable for distribution.
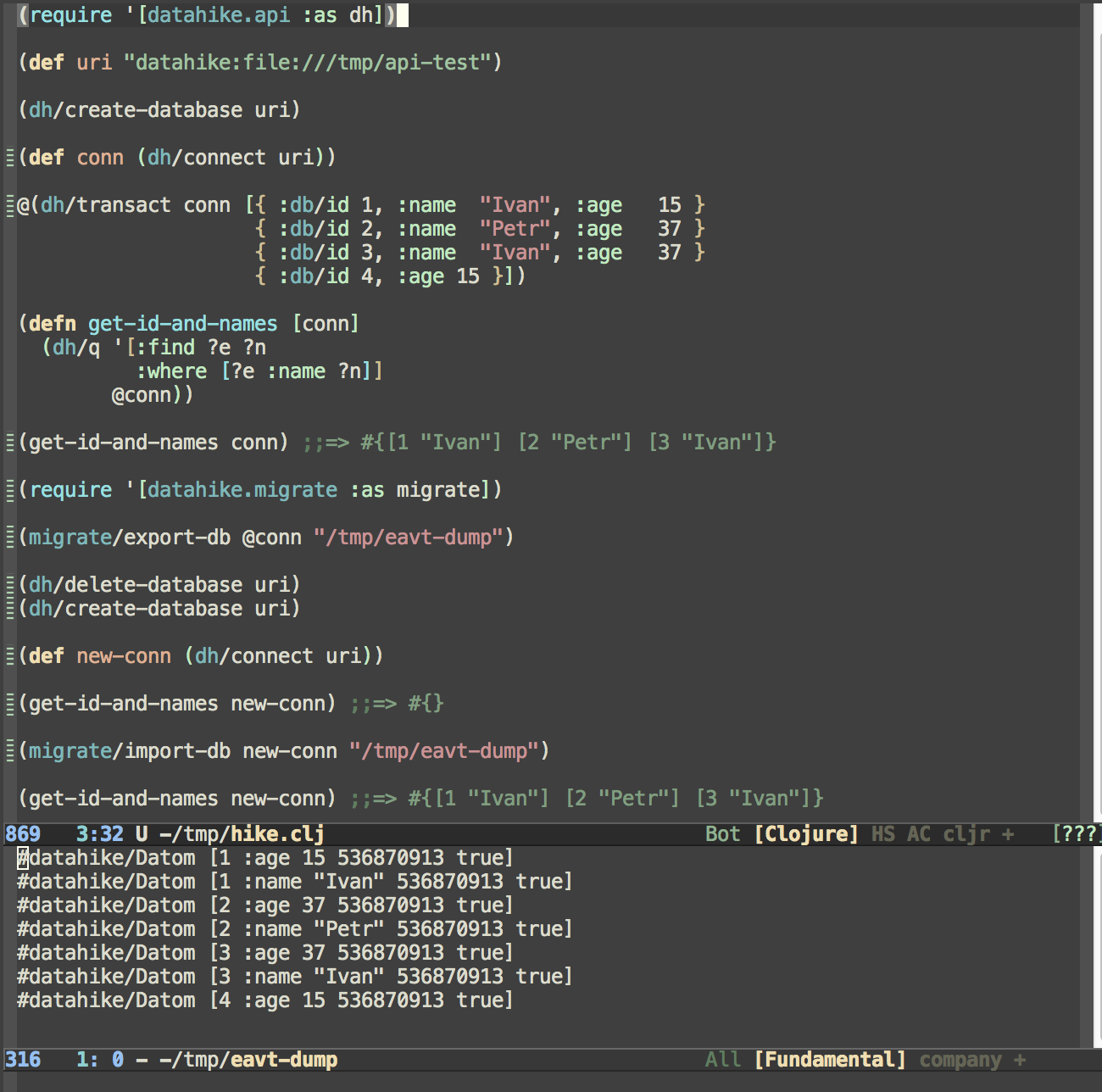
Like DataScript, but durable. Still, not suitable for storing the DB directly as pretty printed EDN, but it has an import/export mechanism which allows you to store the datoms under version control. You could run the import on application startup and hook up the export as a pre-commit hook. You get to use datalog as your query language which is awesome.
datahike supports the same functionality, but this obviously requires to at least hold all data of the edn-serialization in memory (well, you can do reading so that even this is not necessary). Additionally datahike provides the mentioned line-based export and import feature for the EAVT index.
The right way to do it imo is to snapshot the database. Datomic does this automatically with its as-of history capabilities. It is not hard to implement, since datahike already uses persistent datastructures on disk (hitchhiker-trees). The easiest way atm. is to manually copy the :db key (which contains the database) from the underlying konserve store (filestore/leveldb) to some history (e.g. a separate konserve append-log) after you have called transact.
I still need to sort out the history stuff and improve the datahike implementation. If somebody is interested in helping out, feel free to join.