I cannot seem to acquire the code examples for assoc (see where it says " 9 EXAMPLES" and below on the docs for assoc), and my best guess is that the examples are dynamically loaded after the page has already been scraped. I see a few enlive tutorials to try, and then also, I’m keen to understand conceptually what is going on, and what are my next best options, before “blindly” doing a bunch of tutorials with the hope of bumping into my particular use case recipe / “how to”.
In short, do you have any higher level resources, concept maps, etc. that might make this beginner web-scraper (me) level up a bit more smoothly/quickly? Please and thank you!
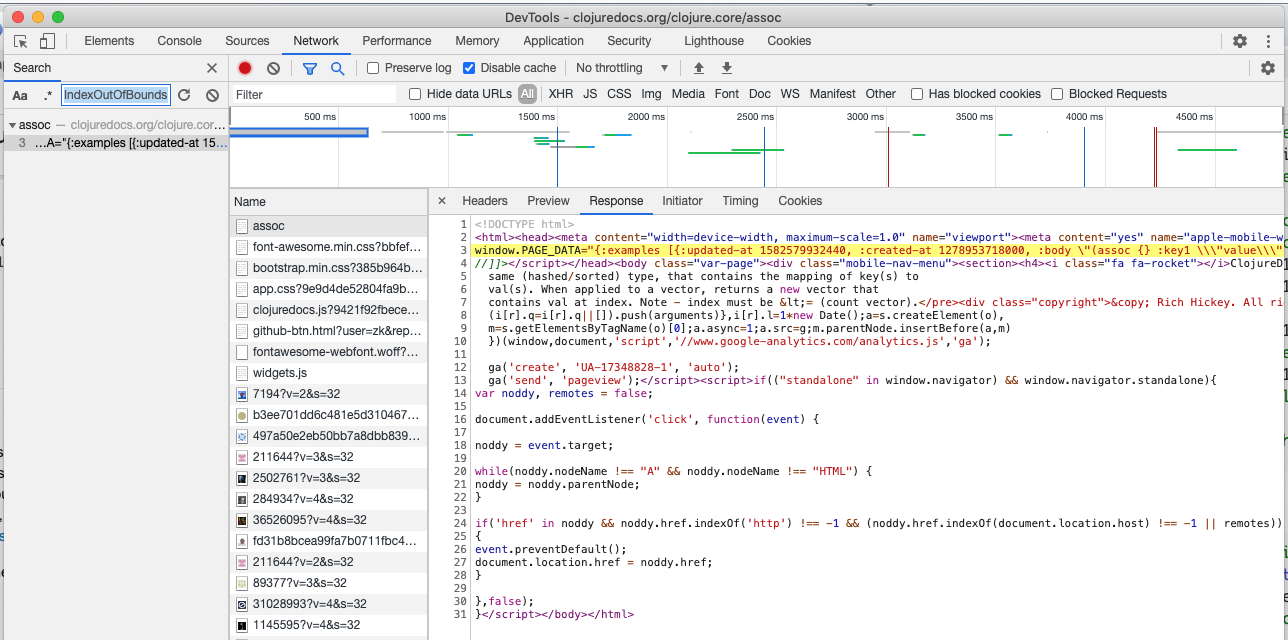
Clues: Using the dev tools in my browser, I am seeing saved to the window something called “PAGE_DATA” which appears to hold some examples. This can be seen in the network tab as well as the elements tab, hanging out in a script tag in the head of the page.
Web-Scraping in general is a rather difficult subject. Especially nowadays with more and more stuff being driven by JavaScript.
If you open the site manually in your Browser but disable JavaScript first you’ll see that it does not load any comments/examples. So to get those comments you’ll need to evaluate JavaScript which basically requires remote controlling a headless browser.
That makes everything far more complicated than just running a HTTP request to fetch some HTML.
I found the Etaoin library pretty easy to get started with for controlling a headless browser. It has functions like get-element-inner-html that you can use to get the contents of parts of the dom, even if they were loaded dynamically.
After surveying a few options, I’d like to stick to what I can do with just the REPL, ideally. Having to install further dependencies or libraries is something I want to avoid, initially at least, so I can learn how to do the basics first. I may be going about this the wrong way. My inspiration for local code and REPL first, libraries and 3rd party code second, comes from here: https://betterprogramming.pub/how-to-scrape-modern-websites-without-headless-browsers-d871bbd1119e
Unfortunately, I am still unable to local the script that is pulling in examples…
OK, so in this instance, you can do it as you said without a headless browser. It seems that the data for all the examples are loaded in a tag in the head of the HTML page.
The way you can find this out is to use devtools as described in that betterprogramming.pub article you linked to and then Cmd+F to search for some text you know is contained in the examples, e.g. “IndexOutOfBoundsException” (for the assoc page) and then devtools will show you the file and line that contains the text, out of all the network requests.
In terms of parsing, the quick and hacky way would just be to use string matching to grab all the text on the line that begins window.PAGE_DATA= then strip off the first and last few characters and it looks like you’ll be left with an EDN map that you can read in with clojure.edn/read-string
Second the shoutout to etaoin, it’s a much easier route to webdriver than selenium, and I’ve used it to scrape and control some reasonably complex web sites.
If you’re using this to learn about web scraping, then definitely continue! I also recommend Etaoin. But if your main goal is just to get the data, then ClojureDocs provides an export in nice JSON at: https://clojuredocs.org/clojuredocs-export.json. I think it’s updated daily.
Thank you @tobyloxy , @Decweb , and @colinfleming , these pointers are super helpful. I’ve located the examples inside the head of the scraped page, so the data is here, and it is available as a text string that looks like EDN (?). After attempting for a couple hours to convert the text into a Clojure hashmap, I figure I am going about this the wrong way. Here are some of my current questions:
What exactly constitutes EDN - is it simply Clojure notation JSON?
Are there unique rules for how it is written?
What is needed to parse the string text of the examples into a Clojure hashmap for a given clojuredocs page?
Please feel free to correct me if my questions are misguided.
Ps. Colin, I was hoping there was an external downloadable file, thank you for reading my mind haha! I figure this will be particularly useful for checking my work later.
EDN is its own thing, see: GitHub - edn-format/edn: Extensible Data Notation. It’s similar in concept to JSON, but using Clojure data structures and elements. Both Clojure and CLJS have support built in, so you can parse a string like this:
So there’s a big hidden gotcha in that the EDN is actually encoded twice, once as EDN to obtain a string, and again as JSON, which is then written to the page.
Why this genius act of coding? I have no idea (it was like 7 years ago). Maybe it had to do with escaping quotes in the edn string or something. Regardless, you have to double decode that string .
I put together a gist that may help. Good luck on your scraping journey!
Hi all, I’m still working on this problem! Thanks to @zk1 and everyone I believe I can get to original goal, of analyzing the examples and notes for a given clojuredoc listing.

 .
.