Announcing in.mesh
I’m pleased to announce an early sneak peak at in.mesh, a webworker library for Clojurescript. Y’all know how I like to release libraries on holidays, and it’s 4th of July, y’all! ![]()
![]()
![]()
![]()
This library extracts out the non-SharedArrayBuffer (SAB) bits that are in tau.alpha. The security around SABs was uncertain for a while - they settled on requiring new headers (COOP/COEP) on your server, unfortunately hamstringing their usability in some deployment situations - but with that settled, I dusted off the ol’ repo and got another version working here with a demo running here: https://simultaneous.netlify.app/

That all depends on the magic of SABs though. Unlocking their full potential in Clojurescript will require more work around SAB-backed persistent data structures - it’s a longer term effort.
in.mesh just focuses on webworker communciation and allows you to spawn them programmatically. At the moment it still requires you create separate builds - one for the main thread, another for the main worker, maybe more, depending on what kind of repl usability you want - but I’m working on further simplifying it as much as possible. My ideal is getting to a place where you can follow the default quickstart tutorials for regular Clojurescript, shadow-cljs and figwheel, and then just add the in.mesh lib and then start programmatically creating webworkers, without having to deal with extra configuration. A stretch goal is to allow you to build a library on top of in.mesh and then your downstream consumers can also use your library without having to fuss with build configurations - a request also asked for previously here on Clojureverse.
That’s still under development, but in.mesh provides two other innovations that are worth looking into presently: spawning webworkers into a mesh and communicating between them using the in macro - thus the "in" dot “mesh”.
The mesh
By default, in.mesh starts with a :root node. From there, you can spawn others:
(def s1 (mesh/spawn {:x 1}))
s1 ;=> "id/d37f262d-1566-45ad-9904-da671bb0cc9c"
You can also spawn workers with a more unique name:
(def s2 (mesh/spawn {:id ::s2 :x 2}))
s2 ;=> :in-mesh.figwheel.root/s2
Note: spawns immediately return a new ID, but the worker creation is asynchronous. Chaining work synchronously on a worker after creation won’t be available until we can get blocking constructs ported back into
in.mesh.
We now have two branch workers, spawned off of the root worker. In Calva, with the current Figwheel configuration, you can switch between the main thread (screen), root and branch builds:
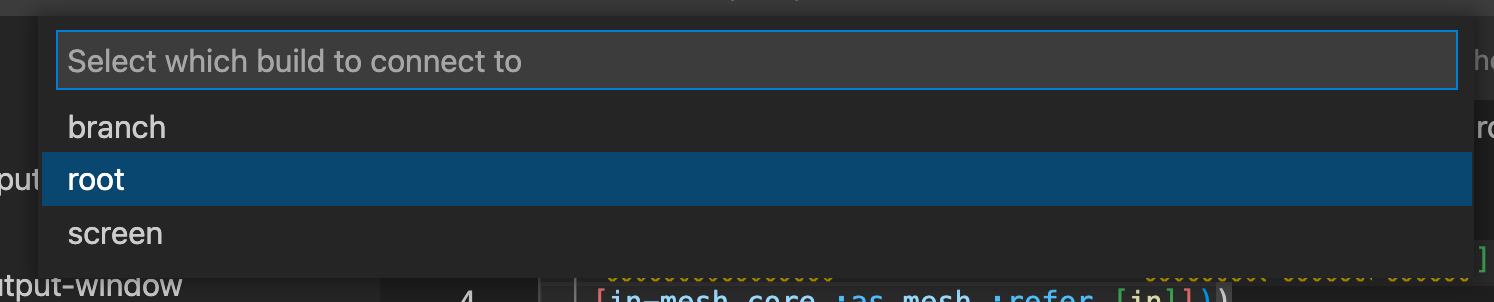
If we require in figwheel.repl’s tools, we can then view the different webworkers connected to a given build:
(conns)
;Will Eval On: Rosie
;Session Name Age URL
;Rosie 0m /figwheel-connect
;Tanner 5m /figwheel-connect
;=> nil
Let’s switch to Tanner:
(focus "Tanner")
;"Focused On: Tanner"
Let’s see Tanner’s peers:
(keys @mesh/peers)
;=> ("root" "s2")
Hmm, Rosie should be ::s2. That’s a bug.
Bottom line, every time you spawn a worker, it automatically creates a connection to all other workers, creating a fully connected mesh. This makes communication between workers fairly transparent and low ceremony.
The in macro
Let’s send a message to “s2”:
(in "s2" (println :hi :from :s2))
;:hi :from :s2
(in "s2" (println :my-id-locally-is (:id mesh/init-data)))
:my-id-locally-is :in-mesh.figwheel.root/s2
The symbol mesh/init-data is being resolved on the “s2” side.
mesh/init-data
;=> {:id "id/64f6525e-4974-43fb-9ad5-6876a0b8ee00", :x 1}
Notice our ID is no longer :root because we switched to Tanner.
Local binding conveyance
The in macro will also automatically convey local bindings across the invocation:
(let [some-name :sally]
(in "s2" (println :hi some-name)))
;:hi sally
Even locally bound functions get conveyed:
(let [some-name :sally
fix-name (fn [x] (keyword x))]
(in "s2" (println :hi (fix-name some-name))))
;:hi :sally
Not everything works, obviously, (some things can’t cross the serialization boundary) and only the scope of locally bound variables get conveyed - not everything at the top level scope:
(def some-name :sally)
(let [fix-name (fn [x] (keyword x))]
(in "s2" (println :hi (fix-name some-name))))
;:hi nil
Note: In this configuration, :branch nodes are sharing the :root build config, so saving the file and thus redeploying the code for the saved namespace will result in branch nodes also having
some-namedefined within the same namespace, so sometimes it will just work, without any conveyance. I’m executing all of these in a comment block at the moment, so that you can see how conveyances are scoped in communication between build-separated clients.
Bound variables within functions also work:
(defn print-in [id some-name]
(let [double-name #(str (name %) "-" (name %))]
(in id (println :hi (double-name some-name)))))
(print-in "s2" :bob)
;:hi bob-bob
For situations where the automatic binding conveyance isn’t doing the trick, you can convey bindings manually:
(def some-name :sally)
(let [fix-name (fn [x] (keyword x))]
(in "s2"
[fix-name some-name]
(println :hi (fix-name some-name))))
;:hi :sally
You can’t currently mix the two techniques together though - patches welcome.
Now let’s do some in chaining:
(def bob (mesh/spawn {:id "bob"}))
;repl.cljc:371 REPL eval error TypeError: Cannot read properties of null (reading 'postMessage')
Ah crap, that’s a bug - we route all spawning activities to the :root node and their IDs are getting turned into strings, so the spawn function is broken for non-root nodes at the moment. Should be an easy fix. Let’s switch back to the root node for creating new workers for now:
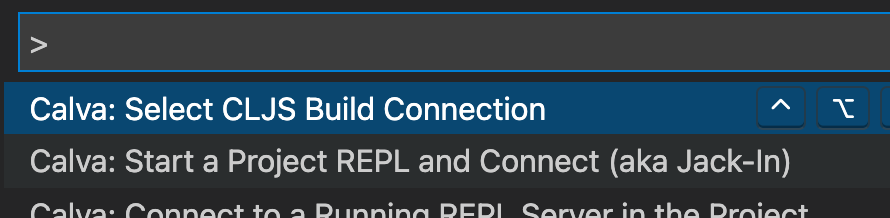
And then click root:
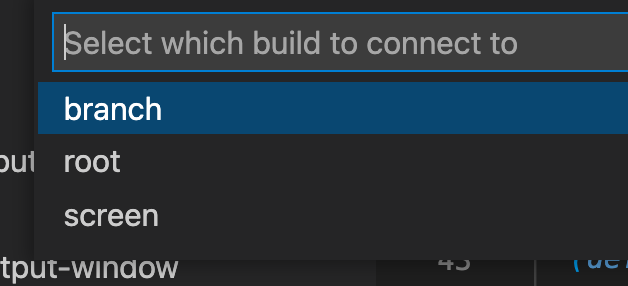
Okay, now let’s try our in chaining:
(def another-name :bill)
(in ::s2
[another-name]
(println :hi another-name :from (:id mesh/init-data))
(in "bob"
(println :hi another-name :from (:id mesh/init-data))))
;:hi bill :from :in-mesh.figwheel.root/s2
;:hi bill :from bob
Here we created a new value :bill; we conveyed that value to ::s2 and printed that value and the local ID; then we implicitly conveyed that value to "bob", printed it and then printed bob’s local ID.
In prior iterations of tau.alpha, I implemented more complex mechanisms like an executor service and an implementation of Clojure’s agents on top, all using this in chaining formalism. It’s a lot easier to reason about the flow of data between workers when you don’t have to construct a new RPC handler for every possible kind of message and logic you want to use.
Anyway, there’s more to delve into but that’s probably a good intro for now. Again, my hope is that we can boil the build configurations down to the simplest possible thing, perhaps eliminating manual configuration altogether. The repo contains /figwheel, /shadow and /cljs example project folders and the Figwheel one is currently the most usable, but the Shadow one should be fixed up soon.
And I hope in.mesh can develop into a solid base for building higher level constructs on top of, including tau 2.0.
Finally, in the spirit of Independence Day, I’d like to celebrate the freedom that Clojure’s power and simplicity allows for - I couldn’t imagine hacking together these kinds of tools in a language that doesn’t give you the ability to redefine itself. So thanks to everyone involved, cheers!!! ![]()
![]()
![]()
![]()
![]()