Thank you, Alex for your rundown and for the video links! I just watched them— exactly what I was looking for.
Daniel’s talk is fun. He motivates the deep-dive as a way to discover the “magic” behind Rich Hickey’s ant demo (all chalking up to these humble things called Vars). It’s full of good related nuggets that are squeezed into the talk, and the end is a fun historical picture of the genesis of the “direct linking” feature I believe.
Gary’s talk is a great explanation of all the side effects of eval’ing a namespace, and how the *__init.class file is created to try to perform all the same side effects as a full eval. It seems there can be a disparity between loading that vs a full eval though sometimes [1][2], which I’ve also experienced but haven’t been able to isolate well enough yet. This talk is a great starting point though:
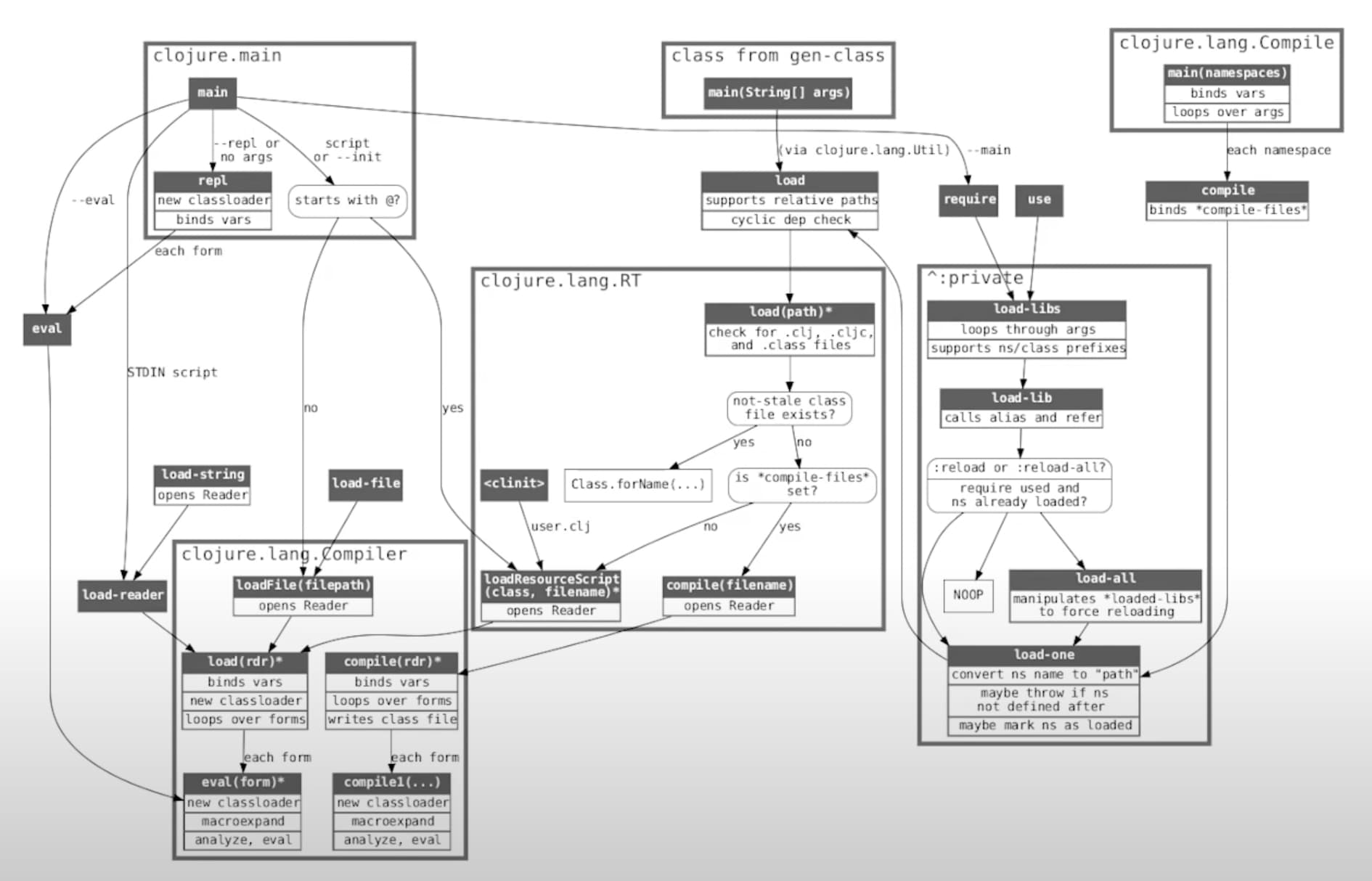
Related to bytecode caching— Alex, I noticed you said this a few years ago:
The place that is the most interesting to me is in reducing the time per-ns and per-var to load code… If code is not AOT compiled (which is where we live at dev time), then we need to look at the time to read, compile, and load the code. There might be opportunities to cache certain parts of this process (given that most of our code is identical every time we load it).
We have a large codebase where 68% of our 40s startup time is spent in clojure.lang.Compiler.analyze*. Maybe a naive (but non foolproof) idea for faster dev reloads is to cache the analyzed expression of each top-level form in a namespace, just using source text— is this what you meant? Still trying to get my head around what might be possible.