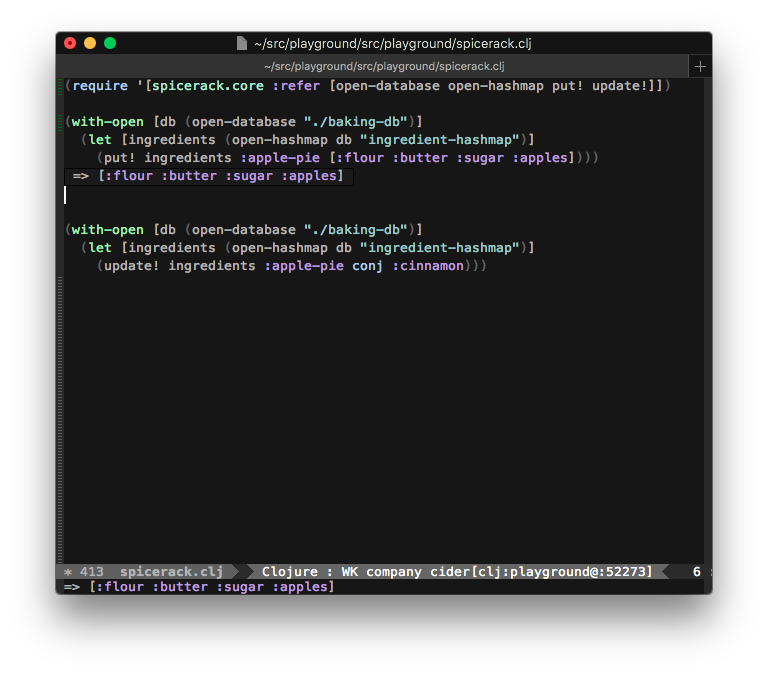
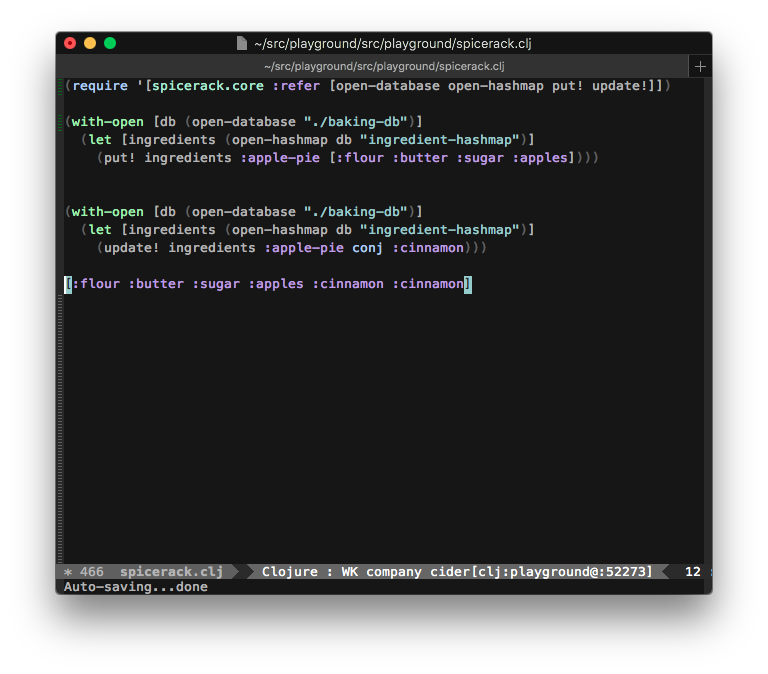
I have two main projects right now. One is an CLJS app for work, the other is an open-source library that I primary develop using CLJ (it supports CLJS, but most of my development is in Clojure). My answers are slightly different for each.
 What kind of REPL do you use—command-line, CIDER’s REPL buffer, or integrated with your project files? If a file, which ones?
What kind of REPL do you use—command-line, CIDER’s REPL buffer, or integrated with your project files? If a file, which ones?
CLJS-app: I start lein repl in the terminal. I then connect with cider-connect and then run
(use 'figwheel-sidecar.repl-api)
(start-figwheel!)
(cljs-repl)
My workflow might be out-of-date here, but I found that more CIDER features work when I do this - namely code navigation.
CLJ-lib: I start lein repl and use cider-connect.
In both projects, I then will create a (comment) block and start evaluating forms directly from my editor with cider-eval-last-sexp (bound to a keybinding, of course). The results show up inline in my editor.
Occasionally the results are too big too understand. I’m not too good at navigating the cider-inspect-last-result buffer, so instead I run cider-eval-last-sexp-and-replace to put the data right in my comment block. I can then use it directly in subsequent experiments, or name it with let or def.
From there, I tend to build up my expression with lots of tiny experiments, and then extract it to a function.
If I’m investigating a bug with an existing function, I tend to use some combo of:
- Adding
println (usually prefixed with my initials like [:bhb {:x x :y y}] so I can grep for “bhb” to remove all debugging lines)
- Creating an example of the function call, then slowly comment out parts of the function implementation so I can see each step returned.
- Sometimes I’ll use “def” to define vars that mirror the local bindings, and then directly evaluate the inner sexps. I usually do this manually, but I have been trying to use scope-capture more to automate this.
I tend to run git commit -am "cp" (“cp” == “checkpoint”) often, so I can commit experiments, messy code, printlns, etc. When I have a logical piece of work to commit, I’ll clean it up, git reset <sha> to the last “real” commit, and then make a single commit of the total changes.
I use both Emacs+CIDER and Cursive: I write/edit nearly all my code in Emacs+CIDER, but occasionally open Cursive to look at warnings and also for renaming symbols and keywords.
 How do you deal with state in the REPL, such as let bindings or other local vars?
How do you deal with state in the REPL, such as let bindings or other local vars?
This hasn’t historically been much of a problem for me. In CLJS, I can just refresh the browser if I notice a problem, which is rare. And in CLJ (perhaps because my project is a library without much state), I rarely run into bugs with stale state. In the rare cases where this occurs, my tests usually catch the issue quickly (see below)
 Do you save your REPL explorations—other than any “official” result like a def’d function—off to a file? Where? Does that file go into source control?
Do you save your REPL explorations—other than any “official” result like a def’d function—off to a file? Where? Does that file go into source control?
I don’t normally save the REPL explorations. For experimentation outside of any specific project, I’ve been toying with a single project with a single namespace that is just a long log of REPL experiments. That project contains all the various tools I might use and I commit all my experiments, but it’s not part of my normal flow for either of my daily projects.
 Do you write tests directly from what you write at your REPL, or separately? From where you run those tests—the shell, CIDER, only on a CI server?
Do you write tests directly from what you write at your REPL, or separately? From where you run those tests—the shell, CIDER, only on a CI server?
I do convert some of my REPL experiments to tests.
CLJS-app: I run tests on the terminal with karma. They re-run every time I save a file
CLJ-app: I run tests with lein test-refresh. They re-run whenever I save a file.
Although this feedback cycles isn’t as fast as I’d like (especially the CLJS tests, the CLJ tests are pretty snappy), I do like that this protects me somewhat from the occasional bugs resulting from stale state in my REPL.
I also run the full suite in CI, just as a final check (this often catches things like forgetting to commit a file  )
)
 But talking to Clojure devs, I find wide variation in what that means. There are real differences in Clojure/ClojureScript workflow from one person the the next.
But talking to Clojure devs, I find wide variation in what that means. There are real differences in Clojure/ClojureScript workflow from one person the the next. Here are some brainstorming questions, but please feel free to describe your workflow freeform.
Here are some brainstorming questions, but please feel free to describe your workflow freeform. What kind of REPL do you use—command-line, CIDER’s REPL buffer, or integrated with your project files? If a file, which ones?
What kind of REPL do you use—command-line, CIDER’s REPL buffer, or integrated with your project files? If a file, which ones? How do you deal with state in the REPL, such as
How do you deal with state in the REPL, such as  Do you save your REPL explorations—other than any “official” result like a
Do you save your REPL explorations—other than any “official” result like a  Do you write tests directly from what you write at your REPL, or separately? From where you run those tests—the shell, CIDER, only on a CI server?
Do you write tests directly from what you write at your REPL, or separately? From where you run those tests—the shell, CIDER, only on a CI server?

 naming
naming , other are still doing
, other are still doing