I was recently inspired by the conj talk from Christoph Neumann where he has a system where everything is live all the time, and has interconnections between them.
As I understand it he can start and stop individual components, and the rest of the system is fault tolerant and keeps running.
One of the requirements was “keeps running, no matter what”.
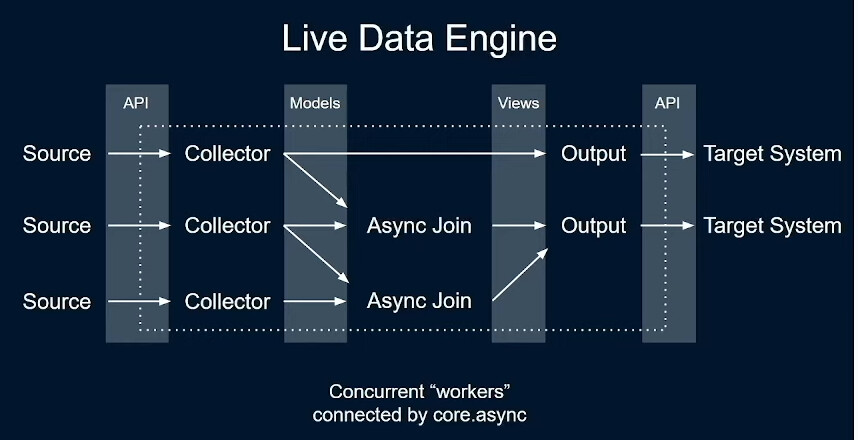
For me this made the concept of ‘architecture’ “click” a bit better. Because it’s not only a structure, but it really drives home that architecture is “the structure that fits the problem”. For me there has been a bit of a disconnect there because I’ve only ever seen architectures in the real world where Conway’s law is in full effect (basically shipping the Org. chart) or been a one man band.
I’ve been going to and from core.async multiple times over a few years. And I think this talk finally convinced me that it’s good. And the bad code I made before was a skill issue.
So I made a new rule based on my new understanding:
Don’t use async functions in your central logic. Ever.
I think this is the biggest antipattern I did, because it hinders good organization of code and async code spreads uncontrollably. I think I’ve read this other places as well.
So I tried to clone the basic idea in a new repo and got some basis(?) functions. Basically wrap some core.async functions into a dumber interface with some decisions taken away from you. Why not directly use the core.async library? because the API is too generic with too many options. I think I finally realized that it is a library that you build libraries on top of. A meta-library so to speak.
The current API of my library consists of:
mapper, aggregator, distributor, input-side-effect, output-side-effect, and, poll!
Which takes care of the following:
channels in and out:
- 1:1 (mapper); basically a call to
a/pipeline - N:1 (aggregator); wraps
a/merge+a/pipelinefor a transducer - 1:N (distributor); wraps
a/mult+a/tapto set up N new channels
edges of the system (apis/functions/IO):
- input-side-effect: function return values sent on a channel (using
Thread/startVirtualThreadfor true async) - output-side-effect: channel values sent to a function using either direct function call to enable backpressure or a virtualThread for asynchronous output.
- poll!: do something every n milliseconds. Required for using most APIs. go block with timeout and function call.
All go-loops check for closed channels, so there will be no abandoned threads/workers.
I first considered using threadpools but I realized it would be cool to dip a toe into project loom as well. I tested it by reading some data from a server.
Error handling I’ve implemented by just log and ‘catch everywhere’ and send it on the output channel as a value. This makes it possible to keep processing after encountering an error.
Demo time:
(require '[core.async :as a])
(defonce system (atom {}))
(defn close-system []
(mapv a/close! (vals @system)))
;; read-data!, printer, counter, filewriter are all normal (non async) clojure functions
;; given the functions described in the post, we can have the entire system definition here:
(defn start-system []
(close-system)
(let [raw (a/chan) ;; channel for raw inputs
[filewriter-c counter-c printer-c] (distributor raw 3) ;; distribute the raw inputs to three channels
]
;; put everthing on the system atom so we can reload
(swap! system assoc :raw raw
:fw-chan filewriter-c
:c-chan counter-c
:p-chan printer-c)
;; every 2000 ms, call read-data! and put it on the raw channel
(poll! input-side-effect read-data! raw 2000)
;; call these side effects with the data from these channels.
(output-side-effect printer printer-c)
(output-side-effect counter counter-c)
(output-side-effect filewriter filewriter-c)))
I think it looks nice. Feels a bit like puzzle pieces.
I have not figured out how to live-insert a new component yet. I think you could do it with some careful partial restarts. But the general case is definetly not hot-swappable. I think it would be cool if it was.
Maybe not useful for the general public. But I think it helps me think about async processing of data, and actually helps me use the core.async library in a cleaner way.
Anybody did stuff like this before? probably, as it feels a bit like some libraries I’ve used before.
Thanks for reading.