Hi Everybody,
I’m in process of writing two apps, one is supposed to transform textual input and simply output a large nested Map (just from that input) and the second will analyze state of an application by executing API calls and again returns a large nested Map.
I’m vague in description since I don’t want to focus on that specific use case. I’d like to kindly ask about structuring application that returns a map of maps.
I tried to do something like this a year ago in Elixir and my surprise was that if your functions “know” internal structure of those data structures then you can get easily into troubles even in functional programming language with immutable data structures.
I’m sure this is not a surprise for you, experienced developers, that if you have a lot of functions that “understand” keys in nested maps, it’s very annoying to change something or to maintain it some time later since you’ll need a lot of time to understand what monstrosity you created a year ago. Not just mentioning that when you start changing stuff then it’s basically refactoring and a lot of tests you wrote will also need to be changed which means you won’t be able to use them to verify that you didn’t break something. I think the official term for this is spaghetti code.
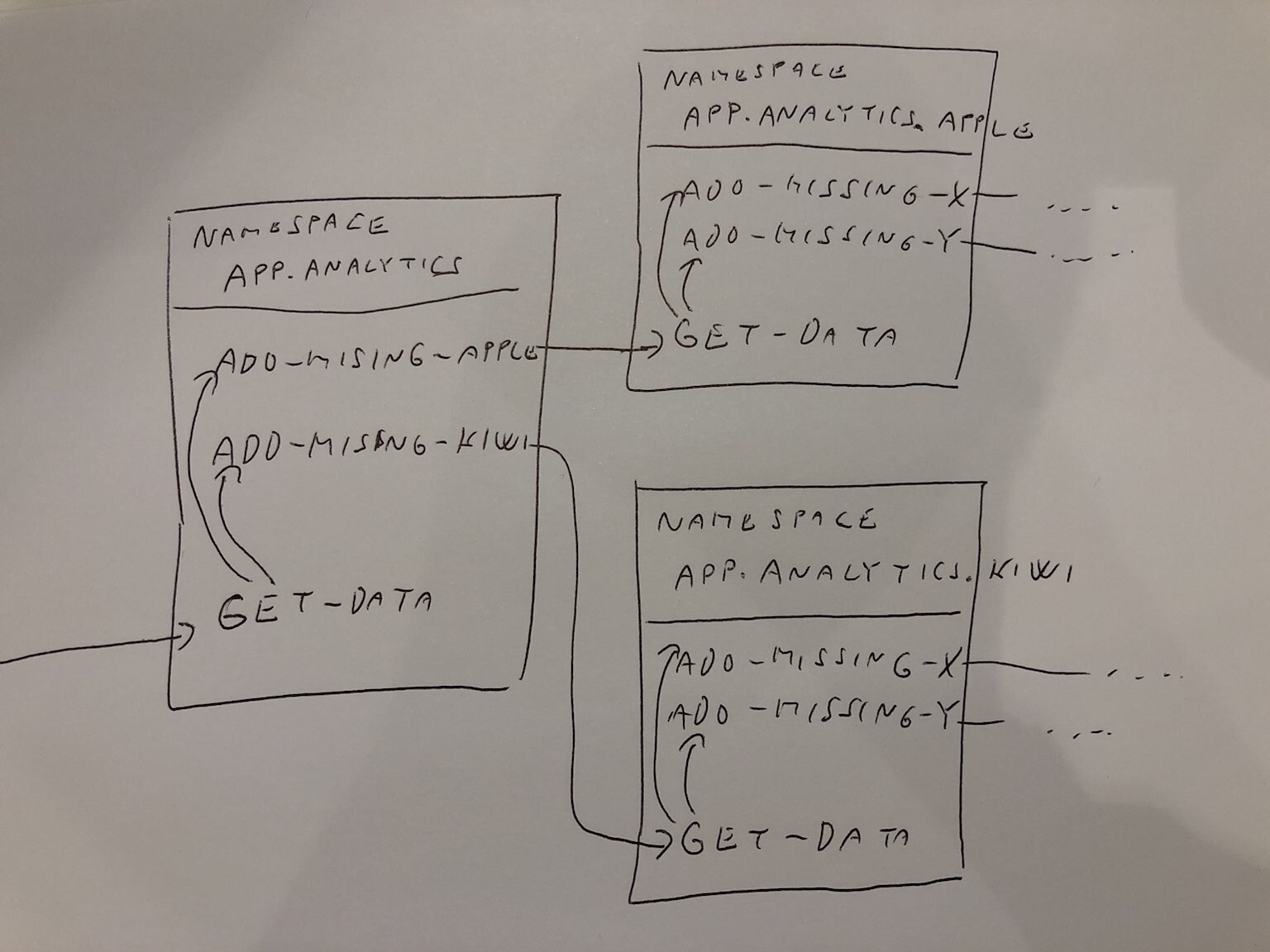
The way how I solved this problem in Elixir is to make sure that functions in one namespace (using Clojure terms) understand only keys in a Map that was also defined in that namespace. In other words I minimized wiring between namespaces.
My first trial (v1.0) was the following:
You can find this and following code in: GitHub - jaydenmcconnell/data-structure-in-clojure
In each namespace the main function is simply called get to highlight that that’s the main one. When you call fruitbasket.analytics/get the function will get all data using simple functions in the same namespace or using get functions in child namespaces - for example by fruitbasket.analytics.fruit.apple/get.
To minimize wiring the get will use only gets in child namespaces. Nothing else in those child namespaces will be called
fruitbasket.analytics.fruit.apple/get can be almost as complicated as fruitbasket.analytics/get since it can call get in its child namespaces. And so on…
(ns fruitbasket.analytics
(:require [fruitbasket.analytics.fruit.apple :as apple]
[fruitbasket.analytics.fruit.kiwi :as kiwi]
[fruitbasket.analytics.fruit.pear :as pear]))
(defn get-something [data]
(count data))
;; opts - idea to use "merge" taken from https://clojureverse.org/t/opts-concept-map-or-vector-with-additional-parameters-as-last-function-argument/7554
(def opts-default
{:apple-color :red
:kiwi-color :brown
:pear-color :yellow})
(defn get [data & {:as opts}]
(let [;; opts merging
opts (merge opts-default opts)
;; apple functions REMOVES analyzed data, leaving just unanalysed
{:keys [apple, unanalysed-data]} (apple/get data opts)
;; the other functions are simpler - they don't remove analyzed data
kiwi (kiwi/get unanalysed-data opts)
pear (pear/get unanalysed-data opts)
;; and something simple that is just in this namespace
something (get-something unanalysed-data)]
{:apple apple
:kiwi kiwi
:pear pear
:something something}))
(ns fruitbasket.analytics.fruit.apple
(:require [clojure.string :as str]))
(defn get [data opts]
;; just a silly example that some analytics functions removes
;; analyzed data so subsequent analytics functions have easier job
(let [[unanalysed-data, color] (if (str/includes? data "GreenApple")
[(str/replace data "GreenApple" "") , :green]
[data, (:apple-color opts)])]
;; returning result AND rest of data (unanalyzed data)
{:unanalysed-data unanalysed-data
:apple {:color color
:count 3}}))
(ns fruitbasket.analytics.fruit.kiwi)
(defn get [data opts]
;; just stupid example
{:color (:kiwi-color opts)
:count (count data)})
(ns fruitbasket.analytics.fruit.pear)
(defn get [data opts]
;; just stupid example
{:color (:pear-color opts)
:count (count data)})
- and run:
(require 'fruitbasket.analytics)
(fruitbasket.analytics/get "GreenApple BrownKiwi YellowPear")
;; =>
;; {:apple {:color :green, :count 3}
;; :kiwi {:color :brown, :count 21}
;; :pear {:color :yellow, :count 21}
;; :something 21}
With such encapsulation (in my opinion) it’s easy to build a complicated app that is gathering information that is then returned as one large nested map.
The only problem is that this would work as my first version but my plan for another version is to limit amount of gathered/analyzed data by specifying what you actually want.
My second trial (v1.1) was the following:
The idea is that all fields are assoc using add-missing-x functions. They can do something simple or call get function in child namespace (only get function, nothing else).
(ns fruitbasket.analytics
(:require [fruitbasket.analytics.fruit.apple :as apple]
[fruitbasket.analytics.fruit.kiwi :as kiwi]
[fruitbasket.analytics.fruit.pear :as pear]))
(defn add-missing-apple [structured data opts]
;; apple function is more complicated than other
;; since it REMOVES analyzed data, leaving just unanalysed
(let [{:keys [apple, unanalysed-data]} (apple/get data opts)]
{:unanalysed-data unanalysed-data
:structured (assoc structured :apple apple)}))
(defn add-missing-kiwi [structured data opts]
(assoc structured
:kiwi (kiwi/get data opts)))
(defn add-missing-pear [structured data opts]
(assoc structured
:pear (pear/get data opts)))
(defn add-missing-something [structured data]
;; and something simple that is just handled in this namespace
(assoc structured
:something (count data)))
;; opts - idea to use "merge" taken from https://clojureverse.org/t/opts-concept-map-or-vector-with-additional-parameters-as-last-function-argument/7554
(def opts-default
{:apple-color :red
:kiwi-color :brown
:pear-color :yellow})
(defn get [data & {:as opts}]
(let [;; opts merging
opts (merge opts-default opts)
;; apple functions REMOVES analyzed data, leaving just unanalysed
{:keys [structured, unanalysed-data]} (add-missing-apple {} data opts)]
;; the other functions are simpler - they don't remove analyzed data
(-> structured
(add-missing-kiwi unanalysed-data opts)
;; get this later:
;; (add-missing-pear unanalysed-data opts)
(add-missing-something unanalysed-data))))
(ns fruitbasket.analytics.fruit.apple
(:require [clojure.string :as str]))
(defn get [data opts]
;; just a silly example that some analytics functions removes
;; analyzed data so subsequent analytics functions have easier job
(let [[unanalysed-data, color] (if (str/includes? data "GreenApple")
[(str/replace data "GreenApple" "") , :green]
[data, (:apple-color opts)])]
;; returning result AND rest of data (unanalyzed data)
{:unanalysed-data unanalysed-data
:apple {:color color
:count 3}}))
(ns fruitbasket.analytics.fruit.kiwi)
(defn get [data opts]
;; just stupid example
{:color (:kiwi-color opts)
:count (count data)})
(ns fruitbasket.analytics.fruit.pear)
(defn get [data opts]
;; just stupid example
{:color (:pear-color opts)
:count (count data)})
- and run:
(require 'fruitbasket.analytics)
(fruitbasket.analytics/get "GreenApple BrownKiwi YellowPear")
;; =>
;; {:apple {:color :green, :count 3}
;; :kiwi {:color :brown, :count 21}
;; :something 21}
That gives me two benefits:
-
The main function might have in the second version an argument (for example set
#{:x :y :z}) that specifies what to get => whatadd-missing-xfunctions to call. -
After the Map is created by the main
getfunction it is possible to call a specificadd-missing-xto add a field that was not needed, but now it is required.
(fruitbasket.analytics/add-missing-pear
{:apple {:color :green, :count 3}
:kiwi {:color :brown, :count 21}
:something 21}
"abcdef" {})
;; =>
;; {:apple {:color :green, :count 3}
;; :kiwi {:color :brown, :count 21}
;; :something 21
;; :pear {:color nil, :count 6}}
I would like to kindly ask, what do you think?
Thank you very much for this community.
Kind regards, Jayden