PlantUML ticks those boxes (though the “nice” aspect does require some effort), plus it’s just text, so you can embed it in comments / org-mode files, etc…
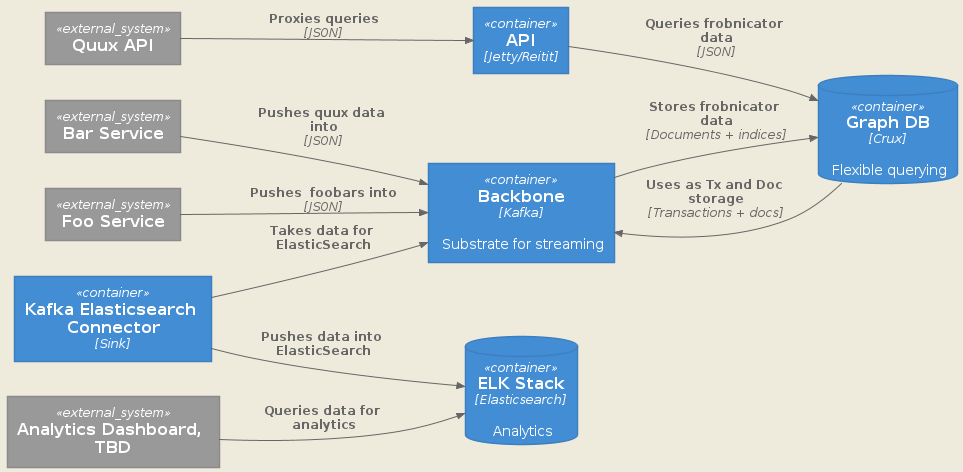
Here’s a scrubbed version of an actual diagram I made for some stuff I’m working on.
The code looks like:
@startuml Architecture
!include /path/to/C4-PlantUML/C4_Container.puml
skinparam backgroundColor #EEEBDC
left to right direction
System_Ext(receiver, "Foo Service")
System_Ext(telemetry, "Bar Service")
System_Ext(omicron_api, "Quux API")
System_Ext(devel_dashboard, "Analytics Dashboard, TBD")
Container(kafka, "Backbone", "Kafka", "Substrate for streaming")
ContainerDb(crux, "Graph DB", "Crux", "Flexible querying")
ContainerDb(elastic, "ELK Stack", "Elasticsearch", "Analytics")
Container(api, "API", "Jetty/Reitit")
Container(elasticconnect, "Kafka Elasticsearch Connector", "Sink")
Rel(elasticconnect, kafka, "Takes data for ElasticSearch")
Rel(devel_dashboard, elastic, "Queries data for analytics")
Rel(elasticconnect, elastic, "Pushes data into ElasticSearch")
Rel(omicron_api, api, "Proxies queries", "JSON")
Rel(receiver, kafka, "Pushes foobars into", "JSON")
Rel(telemetry, kafka, "Pushes quux data into", "JSON")
Rel(kafka, crux, "Stores frobnicator data", "Documents + indices")
Rel(crux, kafka, "Uses as Tx and Doc storage", "Transactions + docs")
Rel(api, crux, "Queries frobnicator data", "JSON")
@enduml
I tend to use org-mode for documenting, and also for literate programming, but unfortunately I haven’t really made it work successfully with my Clojure workflow (RDD is more fluid when done directly from the source files, I find…). I have used it to very good effect with Python, Haskell, Julia, and R in the past, and have always received good feedback on my documentation. To be honest, though, I tend to do it that way since it helps me “rubber duck” my development process, especially when tackling new problems.
Edit: here is an example of literate Python in org-mode: battleship-python/battleship.org at master · mvarela/battleship-python · GitHub